Triton Kernel Mastery: From tl.load to Flash Attention
Write custom GPU kernels in Triton from first principles — the block programming model, masking, fused softmax, autotuning, blocked matmul, and Flash Attention with online softmax, then PyTorch and torch.compile integration. Interview-framed with quizzes and spot-the-bug challenges.

GPU Performance Engineering: CUDA & SYCL
How GPUs actually execute code and how to make kernels fast — the execution model, memory hierarchy, coalescing, bank conflicts, occupancy, the roofline model, warp divergence and reductions, and a profiler-driven optimization workflow. The interview backbone for GPU/perf roles.
GEMM from Scratch: How a Matmul Reaches 90% of Peak
Optimize a GPU matrix multiply step by step — naive kernel, coalescing, shared-memory tiling, register blocking, vectorized loads, tensor cores, and closing the gap to cuBLAS. The canonical 'walk me through optimizing a kernel' interview exercise, with the real speedup numbers.
vLLM & Distributed Kernels: Interview Prep
A FAANG interview bootcamp for LLM inference & distributed GPU systems — PagedAttention, continuous batching, and the vLLM scheduler, then collective communication, ring vs tree all-reduce, NCCL topology, and custom fused all-reduce kernels. Conceptual Q&A, spot-the-bug, and system-design rubrics.
PyTorch Interview Prep: Amateur to Expert
An 8-week FAANG interview bootcamp for PyTorch — tensors and autograd through torch.compile, FSDP2, and ML system design. Conceptual Q&A, live-coding solutions, spot-the-bug challenges, and design rubrics, all on verified PyTorch 2.x APIs.
How vLLM Scales Across GPUs
A WebGL walkthrough of vLLM V1's four parallelism dimensions — tensor, pipeline, Wide EP, and disaggregated serving — with animated all-reduce, pipeline bubbles, expert dispatch, and KV transfer, each grounded in the merged PRs behind it.
vLLM Optimization Deep Dive
Master vLLM's optimization internals through Triton kernel implementations.
NKI Kernel Programming
Program AWS Trainium from first tile to Flash Attention using NKI — the CUDA of Neuron hardware.
The Attention Family: A Visual Guide
A 3Blue1Brown-style WebGL journey through attention and its variants — from Q/K/V and the T×T score matrix to MQA, GQA, MLA, sparse, linear, and FlashAttention, each animated to show how it beats the O(T²) cost.
Staging Large FMA Dots via SLM
Fix the PTSS overflow cliff on non-DPAS Intel iGPUs by staging tt.dot operands in SLM and tiling K.
TD Q-Load for Non-Power-of-2 GQA
When a GPU block-I/O fast path demands power-of-2 extents, pad the awkward axis, read wider, and mask the slack — taught through attention's Q load and prefill tile sizing.
GPU Optimization: 10 vLLM PRs
Learn optimization techniques from actual merged vLLM PRs with verified performance numbers.
PyTorch Optimization: 10 PRs
Learn optimization techniques from actual merged PyTorch PRs with verified performance numbers.

How PyTorch Sees Your Triton Kernel: Using ReLU Kernel in Model with Dynamo and AOT Autograd Backend
How to write Triton Kernel, wire it into model with full gradient support, and then trace the entire …
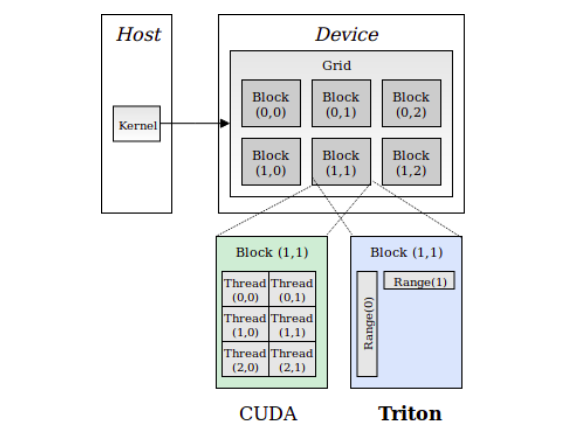
Understanding Triton Kernels from First Principles
A deep dive into how Triton kernels work, explained from absolute basics to complete understanding. …
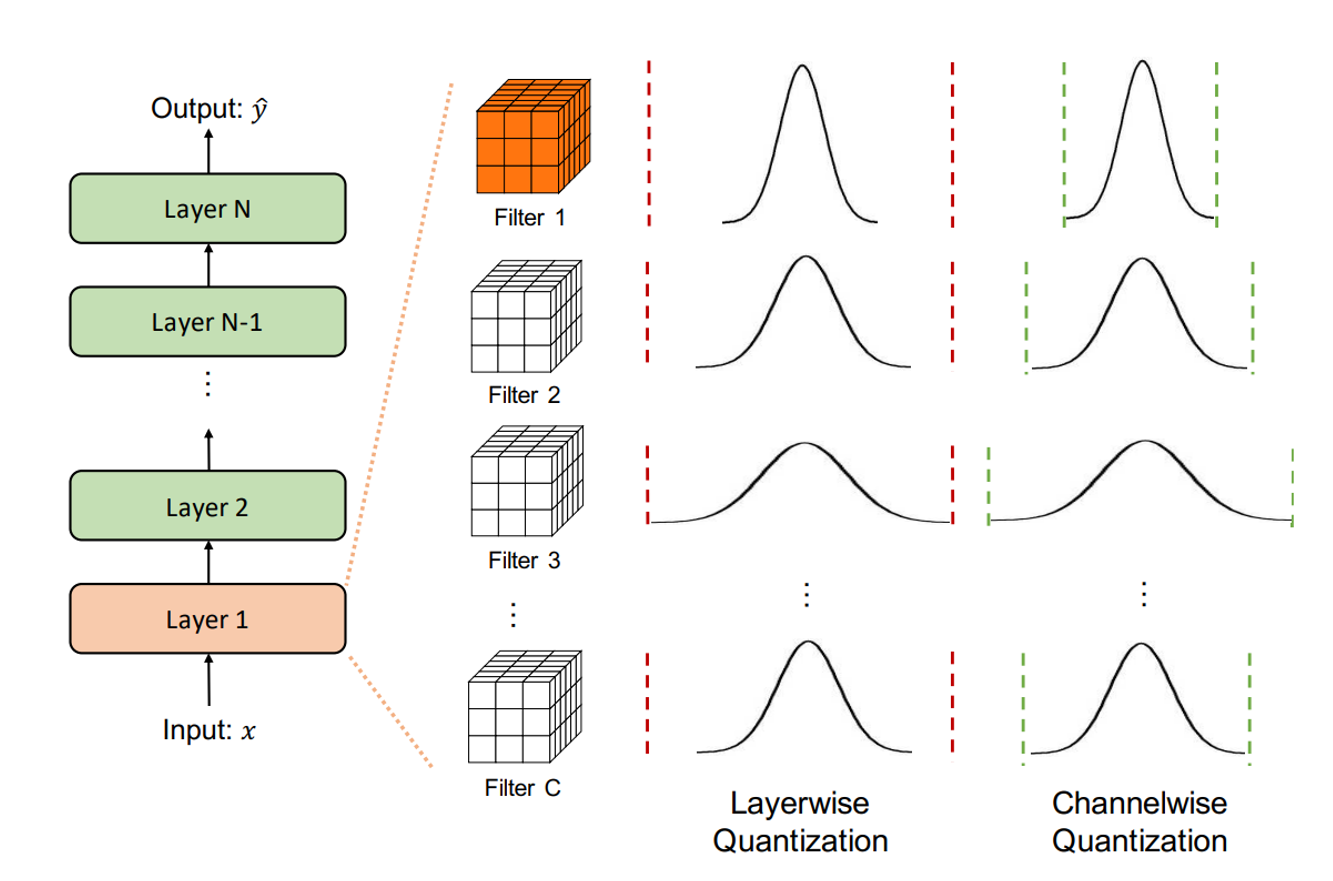
From Theory to Practice: Quantization and Dequantization Made Simple
Quantization transforms floating-point values (‘float32’) into lower-precision formats, such as …
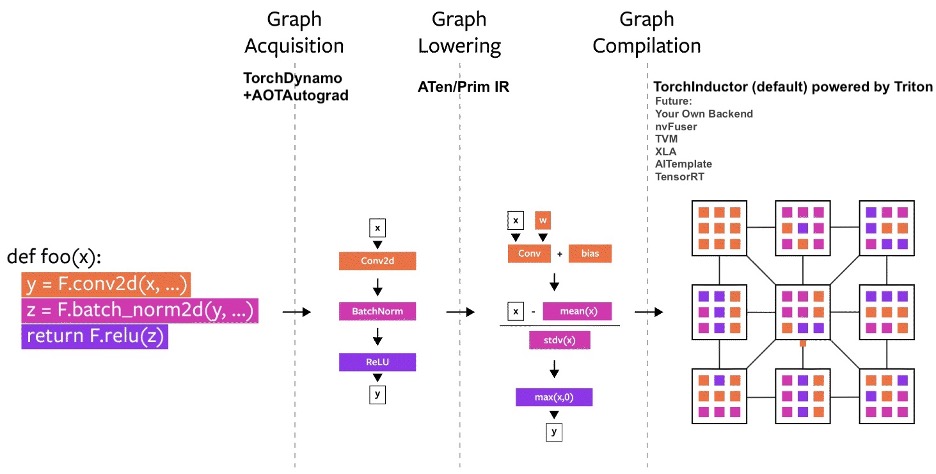
The Simple Path to PyTorch Graphs: Dynamo and AOT Autograd Explained
Graph acquisition in PyTorch refers to the process of creating and managing the computational graph …
All Stories
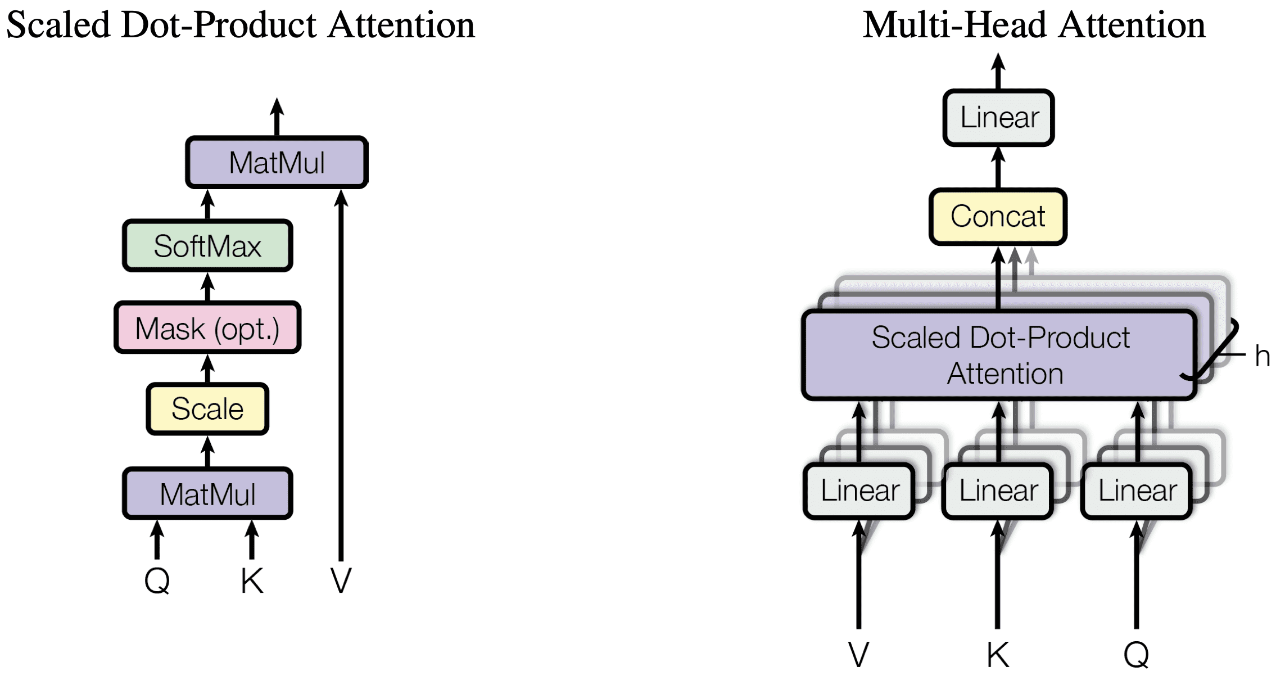
Under the Hood: How PyTorch Chooses Attention Kernels and Why It Matters for Performance
A deep dive into PyTorch’s attention kernel selection and what each choice means for your …

Breaking Down Vision Transformers: A Code-Driven Explanation
In this article, I’ll break down the layers of a ViT step by step with code snippets, and a …
Turn 3D Gaussian Splat Files into Stunning Assets in Unity 6
This guide walks you through the process of loading splat files in Unity 6 using the Gaussian …

Intel GPU Scheduling: Exploring Matrix Addition with SYCL and PyTorch
If you’ve ever worked with GPUs, you know how crucial it is to understand how they manage workloads. …

HLSL Ray Tracing: Crafting Realistic Scenes in Unity, One Ray at a Time
Instead of just slapping textures on polygons, ray tracing lets us simulate how light interacts with …
Harnessing Local Llama to Process Complete Projects: How I use AI for code suggestions and refactoring my Projects
We’ll walk through a Python script that leverages the LangChain framework to process a codebase, …
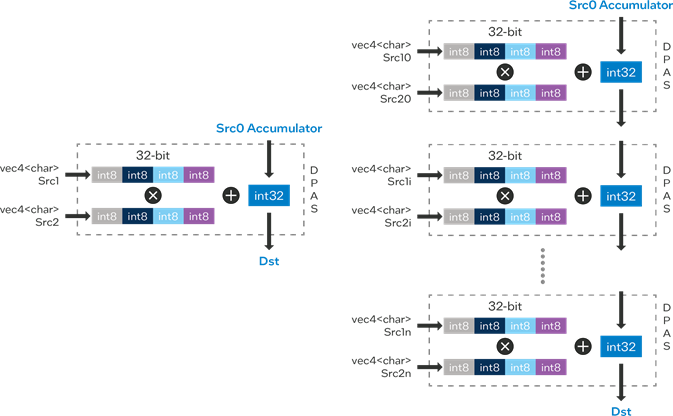
The Magic of DPAS on Intel's XMX Engines: Cracking Why GPUs are Fast
When you think of multiplying matrices, you probably imagine a lot of numbers flying around and …
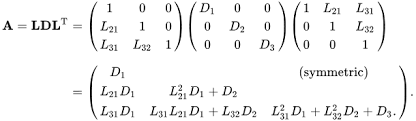
Understanding Cholesky Decomposition with PyTorch
When dealing with symmetric and positive-definite matrices, Cholesky decomposition emerges as an …

Code, Run, Debug on AutoPilot: Let Your Local Llama Do All Your Heavy Lifting!
AutoGen isn’t just another framework; it marks a revolutionary leap in leveraging Large …